Strukturierte Daten: Der Einsteiger-Guide für 2025

Strukturierte Daten (auf Englisch: Structured Data) sind aus der Welt der Suchmaschinenoptimierung nicht mehr wegzudenken. Sie helfen den Web-Crawlern, ein besseres Verständnis von einer Seite zu geben. Warum Du also strukturierte Daten auf Deiner Seite erwägen solltest, erfährst Du in diesem praktischen Einsteiger-Guide.
Inhaltsverzeichnis
Was sind strukturierte Daten?
Allgemein betrachtet sind strukturierte Daten kein reiner Web-Begriff, sondern stehen einfach für die systematische Strukturierung von Daten, um besser gefunden zu werden. Altmodisches Beispiel: Bei der Datenbanksprache SQL (Structured Query Language) bekommen Daten in Tabellenform eine Struktur, um besser in relationalen Datenbanken gefunden zu werden. Auf das Internet übertragen können z.B. Online-Shops ihre Produkte in Kategorien so einteilen, dass diese besser von den Nutzenden gefunden und gekauft werden können. Und wie sieht das in der Suchmaschinenoptimierung aus?
GEO Audit: Wie sichtbar ist Deine Marke in AI Overviews und bei LLMs? 
Erkenne, wie präsent Deine Marke in AI Overviews und Large Language Models (LLMs) ist – und wo noch Potenziale liegen. Jetzt GEO Audit anfragen!
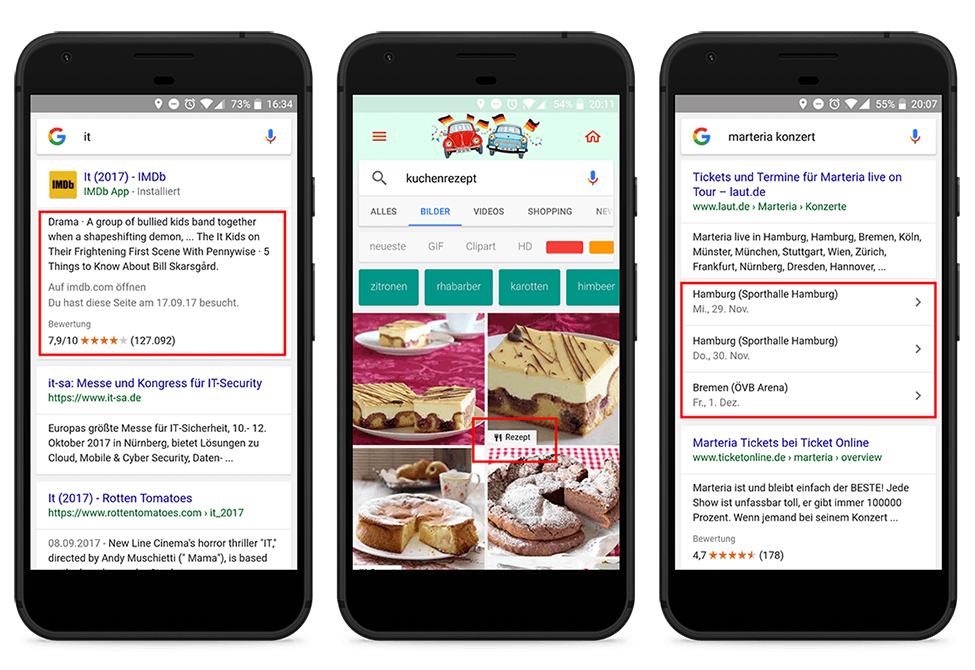
Beispiele für strukturierte Daten
Weitere Beispiele findest Du in der Google Search Gallery.
Gibt es einen Vorteil für SEO?
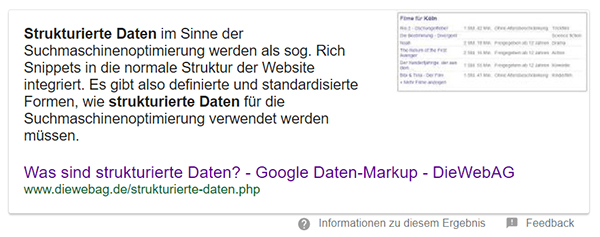
Das Auszeichnen von strukturierten Daten per JSON-LD, Microdata oder RDFa ist per se kein Rankingfaktor, ähnlich wie bei der Meta Description, aber dennoch für die Suchmaschinenoptimierung relevant. Unterscheidet sich ein Ergebnis von der „Konkurrenz“ aber so, dass die Benutzer:innen eher auf Deine Seite klicken, so erhöht sich die Klickrate und die Verweildauer auf der Seite. Bei beidem handelt es sich um einen von mehreren hundert Rankingfaktoren, welche die Relevanz der Seite für User:innen erhöhen können. Man kann also festhalten, dass Deine Seite mit hochqualitativem Content und einem ansprechend hervorgehobenen Suchergebnis eine höhere Chance auf einen Klick hat als eine Seite ohne. Hierbei wird aber immer angenommen, dass Deine Seite im Vergleich zur Konkurrenz die Suchintention der jeweiligen User:innen mehr erfüllt. Zu hervorgehobenen Ergebnissen zählen auch andere Featured Snippets:
Relevanz im E-Commerce
Hast Du einen Online-Shop und erwägst den Einsatz von strukturierten Daten? Gerade hier kann es sich lohnen, da in der Welt des E-Commerce meist ein stärkerer Wettbewerb herrscht und daher jede Information zählt. Wenn man sich auf den SERPs bereits hier von der Konkurrenz abheben kann, kann dies schon die halbe Miete sein. Das liegt daran, dass man User:innen auf den Suchergebnisseiten einfach mehr zeigen kann als andere Seiten und sich dies auch besonders mobil bemerkbar macht.
Zwei Beispiele visualisieren diesen Ansatz: Wenn der User:innen sich beim Suchen fragen wie „Wie teuer ist das Produkt?“ oder „Ist das Produkt denn auf Lager?“ stellt, könnten diese direkt auf Google beantwortet werden. Wenn diese Fragen bereits auf den Suchergebnisseiten beantwortet werden, sind sie ggfs. schon ein Level weiter im mentalen Kaufentscheidungsprozess.
Fünf Beispiele im E-Commerce
1. Anzeige von Bewertungssternen
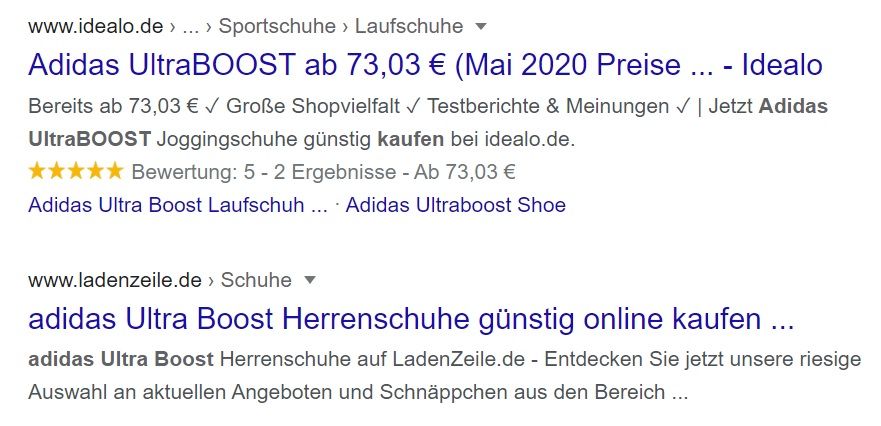
- Das brauchst Du dafür: Kundenbewertungen auf Deiner Seite mit ausgezeichnetem AggregateRating Schema.
- Darum lohnt es sich: Können User:innen auf den Suchergebnisseiten schon informieren, ob sich ein Produkt ggfs. lohnt. Psychologisch wirken sie als eine Art „Social Proof“ (andere User:innen bewerten es gut, also scheint es gut zu sein?).
2. Anzeige von Preisspannen

- Das brauchst Du dafür: Verschiedene Preise auf Deiner Seite mit ausgezeichnetem AggregateOffer Schema.
- Darum lohnt es sich: Können User:innen auf den Suchergebnisseiten schon informieren, ob das Produkt verschiedene Preise besitzt (z.B. anderes Material oder andere Qualität). Sie haben dann direkt die Preisspannen im Hinterkopf.
3. Anzeige von Fragen & Antworten
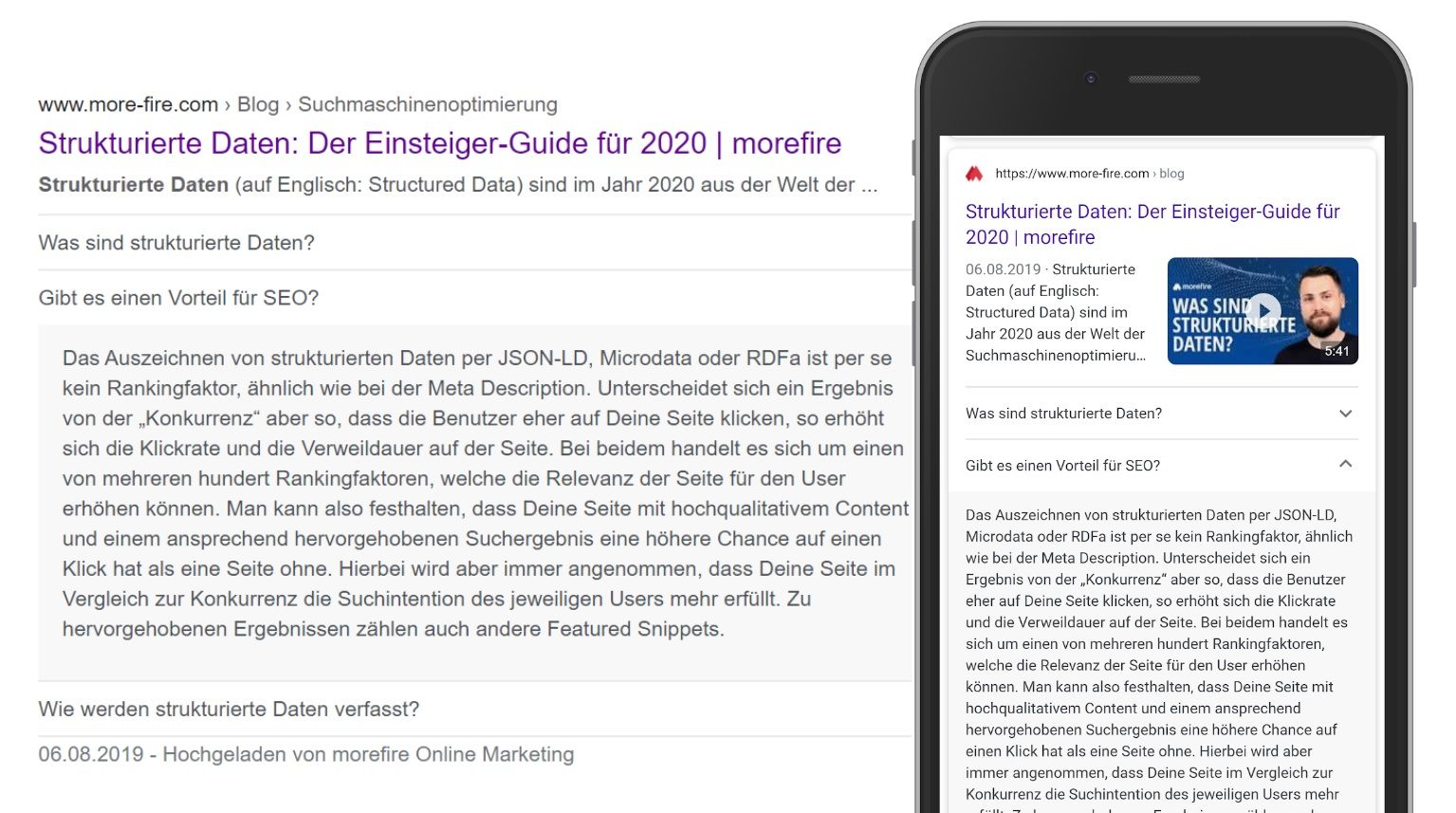
- Das brauchst Du dafür: Einzelne Fragen & Antworten auf Deiner Seite mit ausgezeichnetem FAQPage Schema.
- Darum lohnt es sich: Du kannst bereits auf den Suchergebnisseiten auf mögliche Fragen der User:innen eingehen. So kannst Du bereits hier Interesse erzeugen und nimmst zugleich einen großen Platz in den Suchergebnissen ein.
4. Anzeige von Veranstaltungen
- Das brauchst Du dafür: Veranstaltungen inkl. Details auf Deiner Seite mit ausgezeichnetem Event Schema.
- Darum lohnt es sich: Deine User:innen können bereits auf den Suchergebnisseiten auf Deine Veranstaltungen im E-Commerce Bereich klicken. Eine Link zur Ticket-Seite kann man im Schema verlinken. Gerade mobil fällt dies sehr stark auf.
- Auch interessant: In Krisenzeiten wie Corona & Co. hat Google reagiert und den eventStatus eingeführt. Hier kann man zwischen EventCanceled, EventRescheduled, EventPostponed sowie EventMovedOnline unterscheiden.
5. Anzeige von Kochrezepten
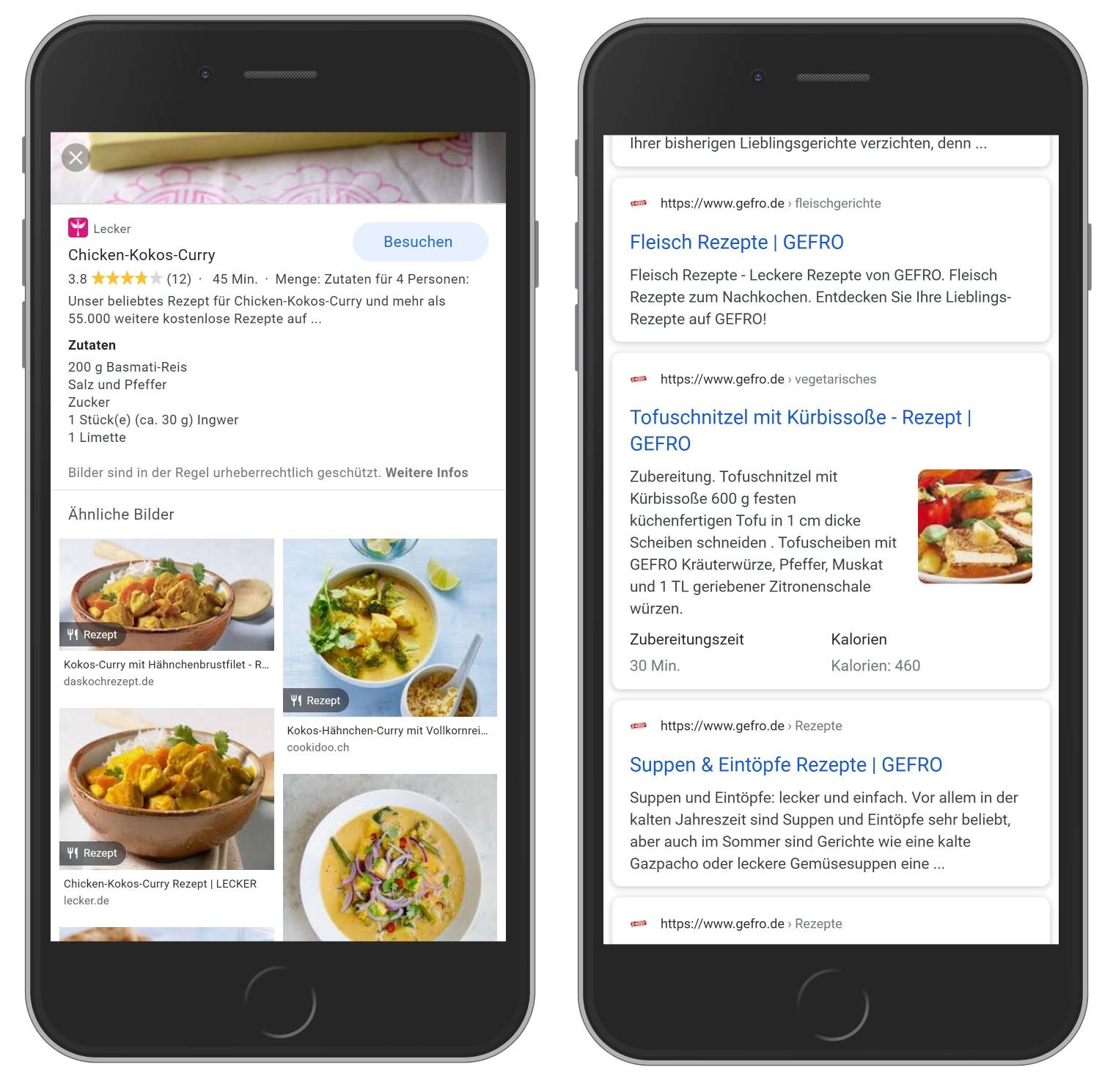
- Das brauchst Du dafür: Rezepte inkl. Details auf Deiner Seite mit ausgezeichnetem Recipe Schema.
- Darum lohnt es sich: Hast Du passende Kochrezepte zu Deinen Produkten? Dann kannst Du diese sehr visuell auf den Suchergebnisseiten darstellen lassen. Gerade bei Rezepten hat man nämlich eine sehr grafische Darstellung
Du möchtest in den Suchergebnissen auf Google und Co. ganz oben stehen? Mit nachhaltiger Suchmaschinenoptimierung ist das möglich!
In unserem ultimativen SEO-Guide bekommst Du alle notwendigen Informationen, um die Sichtbarkeit Deiner Webseite zu steigern..
Wie werden strukturierte Daten verfasst?
Für die einheitliche und browserübergreifende Strukturierung von Web-Daten wurde 2011 eine Initiative mit dem Namen Schema.org gegründet. Sie ist ein Zusammenschluss der Unternehmen Google, Microsoft, Yahoo und Yandex und hat das Ziel, einen gemeinsamen Web-Standard für strukturierte Daten zu schaffen. Geeinigt wurde sich hierbei auf drei verschiedene Ansätze der Strukturierung: Microdata, JSON-LD und RDFa. Diese sollten darüber über alle Browser behandelt werden. Für das Schreiben der Syntax werden bestimmte Vokabeln genutzt, welche sich je nach der Verwendung der Daten unterscheiden.
Microdaten (HTML)
Diese Art der Auszeichnung ist am ältesten und demzufolge auch etwas verstaubt. Hierbei werden reguläre HTML-Tags im Markup mit den Vokabeln von Schema.org ergänzt und um die jeweiligen Seitenelemente „herumgeschrieben“. Man sieht hier direkt im Quellcode, welches Element mit strukturierten Daten angereichert wurde. Der Nachteil bei dieser Variante ist, dass der Aufwand höher beim Auszeichnen ist und der Quelltext etwas unleserlich aussieht. Mehr zum Aufbau der Vokabeln hier.
Code-Beispiel für Microdata:
<div itemscope itemtype=”http://schema.org/Movie”>
<h1 itemprop="name">It (2017)</h1> <span itemprop="description">A group of bullied kids band together when a shapeshifting demon, taking the appearance of a clown, begins hunting children.</span> Director: <div itemprop="director" itemscope itemtype="http://schema.org/Person"> <span itemprop="name">Andy Muschietti</span> </div> Writers: <div itemprop="author" itemscope itemtype="http://schema.org/Person"> <span itemprop="name">Chase Palmer</span> </div> <div itemprop="author" itemscope itemtype="http://schema.org/Person"> <span itemprop="name">Cary Fukunaga</span> </div>, and 7 more credits Stars: <div itemprop="actor" itemscope itemtype="http://schema.org/Person"> <span itemprop="name">Bill Skarsgård</span>, </div> <div itemprop="actor" itemscope itemtype="http://schema.org/Person"> <span itemprop="name">Jaeden Lieberher</span>, </div> <div itemprop="actor" itemscope itemtype="http://schema.org/Person"> <span itemprop="name">Finn Wolfhard</span> </div> <div itemprop="aggregateRating" itemscope itemtype="http://schema.org/AggregateRating"> <span itemprop="ratingValue">7,9</span>/<span itemprop="bestRating">10</span> stars from <span itemprop="ratingCount">127789</span> users. Reviews: <span itemprop="reviewCount">805</span>. </div> </div>
JSON-LD (JavaScript)
JSON-LD ist die aktuellste Form der Auszeichnung und auch die von Google präferierte Lösung. Das Auszeichnen der Vokabeln geschieht hier per JavaScript an einer beliebigen Stelle im Quellcode der Seite. Der Vorteil der Auszeichnung ist also, dass nicht mehr um das Element herumgeschrieben werden muss, sondern in einem zusammenhängenden Skript. Die Lösung ist auch deutlich lesbarer, weil JSON-LD einen schnellen Datenaustausch mit Google und Web-Anwendungen garantieren will.
„Google recommends using JSON-LD for structured data whenever possible.“
Code-Beispiel für JSON-LD:
<script type ="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Movie",
"actor": [{
"@type": "Person",
"name": "Bill Skarsgård"
},
{
"@type": "Person",
"name": "Jaeden Lieberher"
},
{
"@type": "Person",
"name": "Finn Wolfhard"
}
],
"aggregateRating": {
"@type": "AggregateRating",
"bestRating": "10",
"ratingCount": "127789",
"ratingValue": "7,9",
"reviewCount": "805"
},
"author": [{
"@type": "Person",
"name": "Chase Palmer"
},
{
"@type": "Person",
"name": "Cary Fukunaga"
}
],
"description": "A group of bullied kids band together when a shapeshifting demon, taking the appearance of a clown, begins hunting children.",
"director": {
"@type": "Person",
"name": "Andy Nuschietti"
},
"name": "It (2017)"
}
</script>
RDFa (HTML5)
Die Auszeichnung über RDFa findet gefühlt ein Nischendasein in der Strukturierung von Web-Daten. Sie ist eine HTML5-Erweiterung und wird mit anderen Vokabeln ausgezeichnet als Microdata. Hier können auch XML- und SVG-Dateien ausgezeichnet werden, was Microdaten nicht können. Bedingt durch die Präfixe können auch Vokabeln verschiedener Typen miteinander kombiniert werden. Im Vergleich zu JSON-LD ist diese Option nicht so mächtig, aber stärker als Microdaten.
Code-Beispiel für RDFa:
<div vocab="http://schema.org/" typeof="Movie">
<h1 property="name">It (2017)</h1>
<span property="description">A group of bullied kids band together when a shapeshifting demon, taking the appearance of a clown, begins hunting children.</span> Director:
<div property="director" typeof="Person">
<span property="name">Andy Muschietti</span>
</div>
Writers:
<div property="author" typeof="Person">
<span property="name">Chase Palmer</span>
</div>
<div property="author" typeof="Person">
<span property="name">Cary Fukunaga</span>
</div>, and 7 more credits Stars:
<div property="actor" typeof="Person">
<span property="name">Bill Skarsgård</span>,
</div>
<div property="actor" typeof="Person">
<span property="name">Jaeden Lieberher</span>,
</div>
<div property="actor" typeof="Person">
<span property="name">Finn Wolfhard</span>
</div>
<div property="aggregateRating" typeof="AggregateRating">
<span property="ratingValue">7,9</span>/<span property="bestRating">10</span> stars from
<span property="ratingCount">127789</span> users. Reviews: <span property="reviewCount">508</span>.
</div>
</div>
Die Unterschiede zusammengefasst:
- JSON-LD (von Google empfohlen): JavaScript, sowohl im <head> als auch <body> der Seite an beliebiger Stelle möglich. Leichter für Maschinen und Benutzern lesbar und verarbeitbar.
- Mikrodaten: HTML, welches eher im <body> der Seite an spezifischer Stelle um ein Seitenelement geschrieben wird. Änderungen schwieriger umzusetzen.,
- RDFa: HTML5-Erweiterung, welches zusätzliche Elemente und Verknüpfungen im Vergleich zu Mikrodaten unterstützt. Ähnliche Anwendung wie Mikrodaten.
Quelle: In Anlehnung an Google’s Zusammenfassung.

Strukturierte Daten auf der Seite einfügen
Wenn es um die Auszeichnung von Seitenelementen auf der Webseite geht, können viele Varianten verwendet werden. Diese reichen von händischem Einfügen im Quellcode bis zur vollautomatischen Auszeichnung durch Google Produkte. Es gibt hier meiner Meinung nach keine „richtige“ Variante der Auszeichnung, weil es immer auf die Bedürfnisse der Seite ankommt. Daher gibt es sowohl für Einsteiger als auch für „alte Webhasen“ Möglichkeiten, sein Markup auf der Seite auszuzeichnen:
Wichtig: Der Einsatz von strukturierten Daten garantiert nicht, dass die Suchergebnisse auch visuell hervorgehoben werden. Das klingt frustrierend, muss aber so akzeptiert werden. Die beste „Garantie“ ist immer, dass man relevanten Content erstellt, der die Suchintention der Nutzenden widerspiegelt. Google selbst liefert folgende Gründe für dieses Problem:
- Die strukturierten Daten spiegeln nicht den Hauptinhalt der Seite wider
- Die strukturierten Daten wurden falsch ausgezeichnet (falsche Syntax)
- Der ausgezeichnete Inhalt ist vom Benutzer nicht zu sehen
- Die Seite erfüllt nicht die Guidelines, die Google aufgestellt hat
- Der Google Algorithmus bewertet die Seite als nicht relevant für User:innen
Plugins
Eine der einfachsten Möglichkeiten zur Implementation von strukturierten Daten ist das Verwenden von Plugins. Der Vorteil ist, dass die Plugins automatisch für die Auszeichnung sorgen und auch für nahezu jedes Content-Management-System verfügbar sind. Der Nachteil könnte ein erhöhter Pflegeaufwand sein, weil die Plugins aktualisiert werden müssen. Darüber hinaus können Plugins die Ladezeit Deiner Webseite erhöhen, weil einfach mehr Ressourcen geladen werden müssen.
Mit der Version 11.0 des Plugins YOAST ist sowohl für WordPress als auch Typo3 verfügbar. Hier lassen sich mittlerweile auch strukturierte Daten auf Deiner Seite automatisch auszeichnen. Dabei werden auch neuere Schemata (wie zum Beispiel das HowTo-Schema) mittlerweile auch unterstützt, sodass der Aufwand auf Seite des Redakteurs oder Webmasters geringer ist. Die Nutzung von strukturierten Daten und die Implementierung Deine Strategie gehört zu einer laufenden SEO-Beratung.
Empfehlung: Lies Dir die Bewertungen der Benutzer:innen ganz genau durch. Durch die geringe Qualitätskontrolle gibt es zahlreiche Plugins für WordPress, Typo3 oder sonstige Webanwendungen, sodass immer noch „Ente“ unterwegs sind. Wichtig ist auch, dass das Plugin auf einem aktuellen Stand gehalten wird. So wird sichergestellt, dass neue Spezifikationen von Google oder Schema.org (zum Beispiel das Auszeichnen von Stellenanzeigen) beachtet und ausgezeichnet werden.
Google Tag Manager
Bei der Auszeichnung über den Google Tag Manager ist schon etwas mehr Expertise gefragt und viele schwören auf diese Möglichkeit: Einer der Vorteile ist nämlich, dass man das Markup auf der Seite auszeichnen kann, ohne aktiv in den Quellcode einzugreifen (wenn man vom Tag Manager Skript absieht). Während man also mit manuellem JSON-LD noch in den Quelltext muss, spielt der Tag Manager die Auszeichnung automatisch aus. Hierzu schreibt oder generiert man das relevante Code-Schnipsel, erstellt dann ein „benutzdefiniertes HTML-Tag“ und fügt das Code-Schnipsel dort letztendlich ein. Durch „Trigger“ kann das Skript nach dem Veröffentlichen dann auf allen definierten Seiten ausgelöst werden, bei Bedarf auch asynchron.
Empfehlung: War zuvor die Empfehlung, immer den Google Tag Manager zu verwenden (sofern man die Voraussetzungen hat), lohnt sich diese Variante nur noch bedingt. Der Hintergrund hierbei ist, dass der Googlebot den Code nicht direkt im Quelltext sieht und sich erst durch das JavaScript zusätzlich auslesen muss. Vielmehr sollte OnPage-SEO laut John Mueller immer zu sehen sein und den Bot nicht verwirren. Es funktioniert immer noch, verlasse Dich aber nicht darauf.
https://twitter.com/JohnMu/status/1098520235181834240
Manuelles Einfügen
Wer die Expertise in HTML oder PHP hat, kann das geschriebene oder generierte Schnipsel auch direkt in die Seite einbauen. Der Vorteil ist, dass Du ohne Umwege von Tools, Plugins oder Webdiensten die Schnipsel im Quelltext hast. Dabei ist es egal, ob dies in JSON-LD, Microdata oder RDFa geschieht. Sicherlich ist dies auch ein weniger aufwändiger Weg als sich in den Tag Manager reinzufuchsen und dort die Skripte einzubauen. Wer sich nicht mit solchen Sachen rumschlagen will, kann die Schnipsel direkt in den Quelltext einbauen. Der Nachteil ist, dass es hier wenig automatisierte Optionen gibt. Man muss also jedes Seitenelement selber auszeichnen (Microdata) oder jede Seite mit einem JSON-LD Schnipsel manuell ergänzen.
Empfehlung: Bei kleinen Seiten (z.B. private Seiten oder Portfolio-Seiten) kann sich eine manuelle Auszeichnung lohnen, wenn Du Dich nicht mit dem Tag Manager beschäftigen möchtest. Du hast hier immer die volle Kontrolle und bist nicht von anderen Webdiensten abhängig. Es kann aber aufwändig sein, jede Seite manuell zu aktualisieren, sollte sich etwas ändern.
Google Search Console
Der Data Highlighter, den Du in der Google Search Console findest, ist eher ein Tipp zum Experimentieren. Mithilfe dieses Tools kannst Du Seitenelemente auf der Webseite auszeichnen, ohne in den Quellcode einzugreifen. Die semantischen Informationen werden hier nur für Google sichtbar, da diese über die Search Console selber auf der jeweiligen Seite markiert werden. Der Vorteil hier ist, dass ohne jegliche Coding- oder JavaScript-Kenntnisse Elemente ausgezeichnet und getestet werden können. Google bietet hier eine simple Point-and-Click-Lösung an, welche einfach zu befolgen ist: Wähle eine Seite im Tool aus, klicke auf ein Element (z.B. eine Überschrift) und wähle im folgenden Dropdown-Menü die Art der Information aus. Sind alle Elemente markiert, klickst Du auf „Veröffentlichen“ und unterrichtest Google davon. Der Nachteil hierbei ist, dass die Auszeichnung nirgendwo zu sehen ist und dass die Elemente wieder weg sind, sobald die Seite bearbeitet wird.
Empfehlung: Diese Möglichkeit der Implementation würde ich nur als Notlösung oder zum reinen Experimentieren sehen. Gerade bei privaten Seiten oder „Spielballseiten“, die keine SEO-Relevanz haben, kann dies ruhig mal ausprobiert werden.
Wurden bereits strukturierte Daten ausgezeichnet?
Möchtest Du herausfinden, ob eine Seite bereits mit strukturierten Daten ausgezeichnet wurde, kannst Du verschiedene Tools verwenden. Im Rahmen eines Strukturierte Daten Audits bieten sich Dir folgende Optionen an bei der Analyse
1. Testtool für strukturierte Daten verwenden
Google hat ein eigenes Tool entwickelt, welches strukturierte Daten auf der Seite untersuchen kann. Der Vorteil hierbei ist, dass man sofort Fehler, Warnungen oder sonstige Meldungen von Google sehen kann. Taucht hierbei nichts auf, kann angenommen werden, dass keine Daten auf der Seite existieren, über den Google Tag Manager implementiert wurden oder JavaScript verhindert, dass etwas angezeigt wird. Der Nachteil: Alles ist URL-basiert. Du musst Stichproben durchführen.
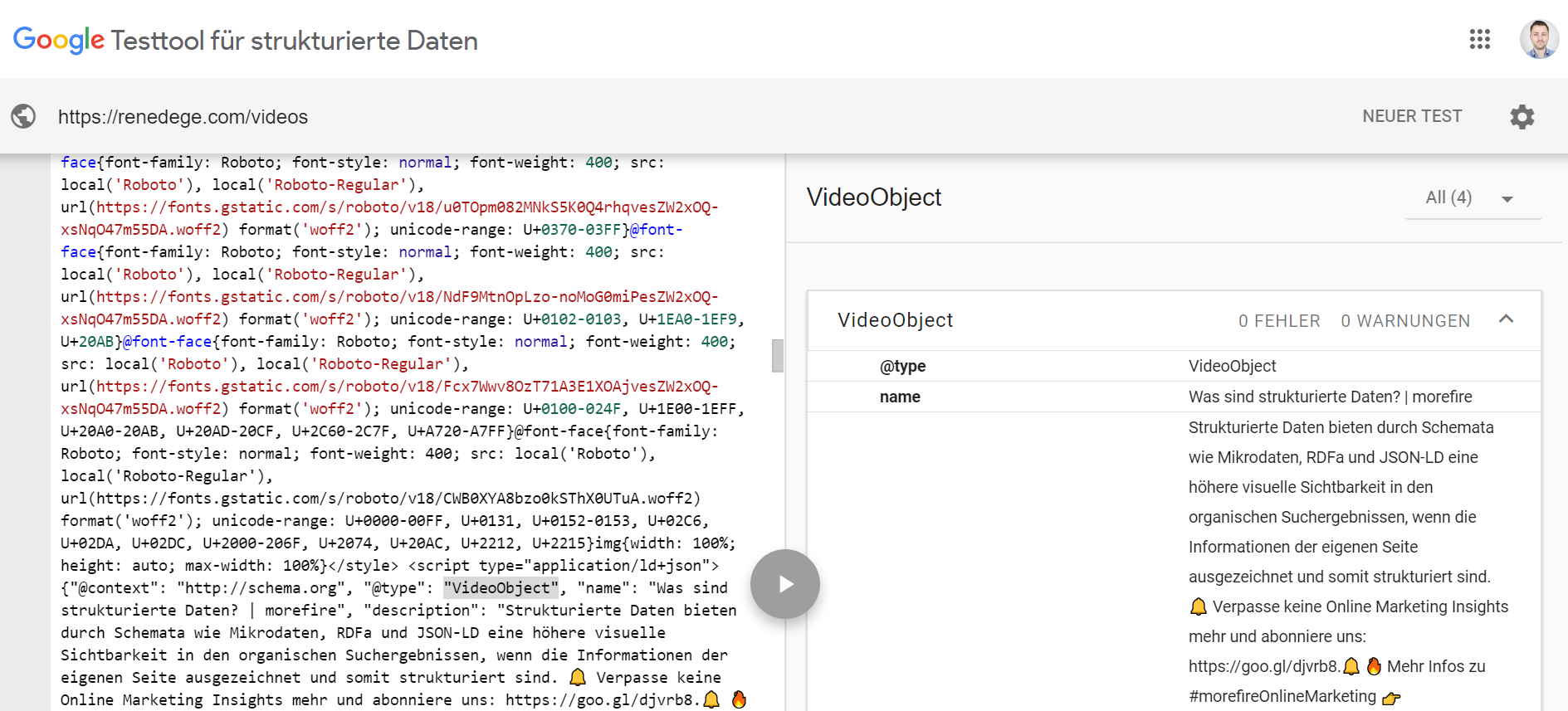
2. Screaming Frog SEO Spider verwenden
Etwas fortgeschrittener ist das Tool Screaming Frog, welches zum festen Bestandteil vieler SEOs gehört. Seit Version 11 gibt es die Option, eine Seite auf strukturierte Daten zu untersuchen. Im Vergleich zum Testtool hast Du somit die Möglichkeit, eine gesamte Seite auf strukturierte Daten zu untersuchen. Ein Vorteil ist auch, dass Du direkt eine Validation der Daten anstoßen kannst, um Bescheid zu wissen. Der Nachteil ist, dass große Seiten sehr lange zum Crawlen brauchen.

Kostenloses E-Book: Erfolg im E-Commerce

Mit strukturierten Daten erfolgreich E-Commerce betreiben. Jetzt in unserem kostenlosen E-Book nachlesen!
Fazit: Im Jahr 2025 noch relevanter
Du hast jetzt einen Überblick über die Möglichkeiten und Vorteile von strukturierten Daten erhalten. Ich hoffe, Du konntest hierbei Potenziale für Deine eigene Seite, Online-Shop oder Unternehmen entdecken. Möchtest Du mehr darüber erfahren, wie man eine Seite auszeichnet, besuche den Schwester-Artikel “Strukturierte Daten Audit: Darauf solltest Du achten”. Fest steht: Strukturierte Daten werden auch im Jahr 2021 weiter an Bedeutung gewinnen. So wird Google mit möglichst vielen Informationen versorgt und gewährt Dir im Gegenzug weitere visuelle Hervorhebungen. Dabei solltest Du aber immer beachten, dass die erfüllte Suchintention des Benutzers immer im Vordergrund stehen sollte.
Bonus: Hilfreiche Ressourcen für strukturierte Daten
Als Neueinsteiger:in kann es sehr schwer sein, sich durch den Dschungel der strukturierten Daten zu kämpfen. Neben diesem Guide gibt es im Internet daher zahlreiche Ressourcen, die einem das Thema näher erläutern. Eine Auswahl findet Ihr hier:
- So funktionieren strukturierte Daten: Der offizielle Leitfaden von Google. Er zeigt sowohl die Datenformate als auch Implementierungsarten auf. Darüber hinaus zeigt er, welche Elemente sich auf einer Webseite alles auszeichnen lassen.
- Search Gallery (Englisch): Dieser englische Guide fungiert als eine Art Showcase zu allem, was mit strukturierten Daten alles möglich ist. Er listet alle Arten auf und ergänzt die Beispiele mit praktischen Code-Schnipseln.
- Test-Tool für strukturierte Daten: Hinter diesem Tool verbirgt sich eine echte Hilfe zur Validierung von strukturierten Daten. Man kann sowohl Code-Snippets als auch ganze URLs einfügen und diese auf Fehlerfreiheit prüfen. Das Tool wird in naher Zukunft jedoch eingestellt und wird dann durch das Rich Result Tool von Google ersetzt.
- Schema Markup Generator (Englisch): Wer auf die Schnelle ein Markup für strukturierte Daten bilden möchte, kann diesen handlichen Generator verwenden. Das Ergebnis wird direkt ausgabefertig in JSON-LD oder Microdata geliefert.
- Ryte structured data helper (Chrome Extension): Als Alternative zum Testtool für strukturierte Daten (was wie erwähnt bald eingestellt wird), hat man bei Ryte eine Extension für Google Chrome erschaffen, um auf einen Blick zu sehen, ob eine Webseite strukturierte Daten nutzt. Auch sieht man direkt etwaige Fehler und Warnungen im verwendeten Markup.