Das Canonical Tag

Beim Canonical Tag handelt es sich um ein Attribut, das einer Suchmaschine dabei hilft doppelte Inhalte (Duplicate Content), die auf mehreren URLs veröffentlicht wurden, im Netz richtig einzuordnen. Oft kommt es zu einem falschen Einsatz mit dem Attribut, sodass Suchmaschinen verwirrt sind und es Probleme mit der Indexierung gibt. Wie man das Canonical Tag richtig einsetzt und welche Fehler häufig gemacht werden, habe ich in diesem Beitrag einmal zusammengefasst.
Inhaltsverzeichnis
- Was ist das Canonical Tag?
- Wie ist ein Canonical Tag aufgebaut?
- Anwendungsfälle eines Canonical Tag
- Häufige Fehler in Verbindung mit Canonical Tags
- Canonical Tag vs. Paginierung
- Absolute URL vs. relative URLs
- Canonical vs. Hreflang
- Canonical vs. mobile Seiten
- Canonical vs. Canonical
- Canonical vs. Startseite only please
- Canonical vs. 301 Redirect aka. unlimited redirect Loop
- Canonical-Weiterleitungsketten
- Fazit
Was ist das Canonical Tag?
Das Canonical Tag wird seit 2009 bei diversen Suchmaschinen (Google, Bing, Yahoo) eingesetzt, um einer Suchmaschine eine bevorzugte Version bei URLs mit gleichem oder sehr ähnlichem Content mitzuteilen. Die Haupt-URL nennt man auch „kanonische URL“. Verweist eine URL mit demselben Inhalt per Canonical Tag auf die Haupt-URL, weiß eine Suchmaschine, welche URL in den Suchergebnissen angezeigt, sprich indexiert werden sollte und welche URL das Duplikat ist. Denn ansonsten kann es dazu führen, dass beide URLs in den Index gelangen und sich gegenseitig die Rankings wegnehmen, was bei der Suchmaschinenoptimierung unbedingt vermieden werden sollte. Somit hat Google es schwer zu verstehen, welche der URLs zum optimierten Keyword ranken soll. Wir sprechen hier quasi von Kanibalisierung auf Keyword-Ebene. Es sei jedoch gesagt, dass ein Canonical Tag bei falschem Einsatz auch gerne von den Suchmaschinen ignoriert wird.
Wie ist ein Canonical Tag aufgebaut?
Das Attribut wird im Headbereich eines Quelltexts innerhalb eines Link-Elements ausgezeichnet und sieht folgendermaßen aus:
<link rel=”canonical” href=”https://www.beispiel.de/original-url/”/>
Es gibt immer nur ein Canonical Tag auf einer Seite. Wird das Canonical Tag mehrfach auf einer URL genutzt, werden diese von den Suchmaschinen ignoriert und die Seite wird weiterhin in den Suchmaschinen-Index aufgenommen.
In Googles Webmaster-Zentral-Blog wird zudem Folgendes in Verwendung mit dem Canonical Tag empfohlen:
- Überprüfung der Inhalte auf den Webseiten auf tatsächliche Ähnlichkeiten
- Vermeidung von 404-Fehlern der kanonischen URL (hier eignet sich am besten der Screaming Frog)
- Sicherstellung, dass die kanonische URL kein „noindex“ Robots Meta-Tag enthält (ebenfalls schnell gelöst mit dem Screaming Frog)
- Überprüfung der kanonischen URL auf Indexierung anstatt der duplizierten URL (schnell geht das mittels Site-Abfrage im Google Index)
- Hinterlegung des Attributs innerhalb des http-Header oder im <head> Bereich der Seite
- Nie mehr als ein Canonical-Attribut pro Seite verwenden
Anwendungsfälle eines Canonical Tag
Ein Canonical Tag wird dann genutzt, wenn Inhalte auf mehreren URLs verwendet werden oder eine einzigartige URL aus technischen Gründen nicht möglich ist. Hier findet Ihr ein paar Anwendungsfälle, wann Canonical Tags genutzt werden:
- Ist eine Seite über diverse URLs erreichbar, beispielsweise http://www.domain.de, https://www.domain.de, http://domain.de, https://domain.de, https://www.domain.de/index.php, kann das Canonical Tag genutzt werden – am idealsten ist es bei diesem Fall jedoch eine 301-Weiterleitung aller Varianten auf die Haupt-URL umzuleiten
- Bei URLs, die mit und ohne Trailing Slash („/“) oder auch in Groß- und Kleinschreibung erreichbar sind und einen 200-Status-Code ausgeben
- Bei Verwendung von Session-IDs oder Produktfiltern (Parametern) innerhalb eines Shops, die den Inhalt jedoch nicht verändern
- Wenn der Inhalt z.B. in einer Druckversion oder auch als PDF angeboten wird
- Bei Nutzung von http-und https-Varianten. Hier sollte man sich jedoch lieber für eine Ressource entscheiden – und zwar https, das seit Januar 2017 ein wichtiger Ranking-Faktor Googles ist. Was man bei der Umstellung von http auf https beachten sollte, erfahrt ihr in Jasper Beitrag
- Zusätzliche Veröffentlichung der Inhalte auf externen Webseiten
In einem Google Webmaster Hangout Juli 2017 gibt John Müller von Google den Hinweis, dass man das Canonical Tag neben Seiten mit Duplicate Content (z.B. Seiten mit Parametern) auf allen Seiten, auch ohne Duplicate Content einsetzen sollte, damit es für die Suchmaschine noch eindeutiger ist, dass es von dieser Version kein Duplikat gibt und die Ressource die Originalversion ist.
Häufiger Fehler in Verbindung mit Canonical Tags
Dass das Canonical Tag ein mächtiges Werkzeug ist, haben wir also bereits kennengelernt. Jedoch gibt es eine Vielzahl von Fällen, bei denen das Attribut falsch angewendet werden kann und es somit zu Fehlern innerhalb der Indexierung kommt, was ein Problem für eine ganze Domain bedeutet. Kommen wir hier also zu den häufigsten Fehlern L und wie man es richtig macht.
Canonical Tag vs. Paginierung
Ausgangspunkt: Eine Kategorieseite verfügt über zahlreiche Produkte, die auf mehreren paginierten Seiten hinterlegt sind.
- www.domain.de/kategorie/
- www.domain.de/kategorie/?seite=2
- www.domain.de/kategorie/?seite=3
- www.domain.de/kategorie/?seite=4
- usw.
Diese Seiten sind via rel=”next” und rel=”prev” ausgezeichnet. Jede paginierte Seite verweist via Canonical Tag auf die Haupt-URL (erste Seite).
Warum falsch?
Wird das Canonical Tag hier eingesetzt, kann die Suchmaschine die Inhalte der paginierten Seiten nicht indexieren und den dort verlinkten Seiten nicht folgen. Die richtige Nutzung des Canonical Tags wird in einer SEO-Beratung sichergestellt.
Verfügt man also über paginierte Seiten sollte man:
1. bei Verwendung des Canonical-Tags auf eine URL verweisen, auf der alle Produkte aufgelistet sind. Beispiel: domain.de/kategorie/?seite=alle
oder
2. der zweiten Seite rel=”next” und rel=”prev” in Verbindung mit „noindex“ einsetzen
Absolute URL vs. relative URL
Im Canonical Tag sind absolute oder relative URLs nutzbar, jedoch beziehen sich relative URLs auf einen Pfad ausgehend von der aktuellen Website. Beispiel eines Canonical Tags mit relativem URL-Pfad:
<link rel=”canonical” href=”beispiel.de/original-url/”/>
Die angegebene, originale URL (relative URL) verfügt über kein http:// und geht von der kanonischen URL „http://beispiel.de/beispiel.de/original-url/“ aus, was somit fehlerhaft ist und der Crawler landet auf einer 404 Seite.
Auch sollten relative URLs wie /originale-URL/ als kanonische URL nicht verwendet werden.
<link rel=”canonical” href=”/original-url/”/>
Nutze stattdessen die gesamte, also absolute URL.
<link rel=”canonical” href=”https://www.beispiel.de/original-url/”/>
Canonical vs. hreflang
Wer Hreflang in Verbindung mit Canonicals nutzt, muss jetzt ganz genau hinschauen. Denn wenn die beiden Attribute auf verschiedene Pfade verweisen, werden falsche Signale an Google gesendet. Die Suchmaschine versucht dann sich selbst zu helfen und entscheidet von alleine welche Seite in den Index soll.
Du willst mehr zum Thema SEO erfahren? Dann findest du hier unseren SEO-Ratgeber!
Beispiel:
Eine URL verweist per Hreflang-Tag auf sich selbst, jedoch per Canonical Tag auf eine andere URL. Die restlichen Sprachversionen verweisen ebenfalls auf sich selbst und per Canonical Tag auf eine andere URL.
Merke: Wenn man Hreflang-Tags nutzt, haben Canonical Tags auf diesen URLs nichts zu suchen.
Wer mehr zu Hreflang wissen möchte, klickt jetzt hier!
Canonical vs. mobile Seiten
Wer über noch keine Responsive-Webseite und stattdessen über eine separate mobile Subdomain z.B. m.domain.de verfügt, sollte auf den mobilen URLs mittels Canonical Tag auf die normale Desktop-Variante verweisen.
Übrigens sollte von der Desktop-Variante auf die mobile Variante mittels rel=”alternate”-Tag verwiesen werden.
Canonical vs. Canonical
Ganz oft schon gesehen, dass auf einer URL mehrere Canonical Tags verwendet werden. Die Suchmaschine ist somit komplett verwirrt und ignoriert sämtliche Angaben. Am besten die Domain mittels Screaming Frog crawlen und sichergehen, dass nur ein Canonical Tag verwendet wurde!
Canonical vs. Startseite only please
Ja, die Startseite ist mitunter die wichtigste Seite einer Domain. Jedoch sollte man nicht von allen Seiten mit einem Canonical Tag auf die Startseite verweisen. Das führt dazu, dass alle Seiten aus dem Index fliegen und nur noch die Startseite im Index landet.
Canonical vs. 301 Redirect aka. unlimited redirect Loop
Nehmen wir mal folgendes Beispiel:
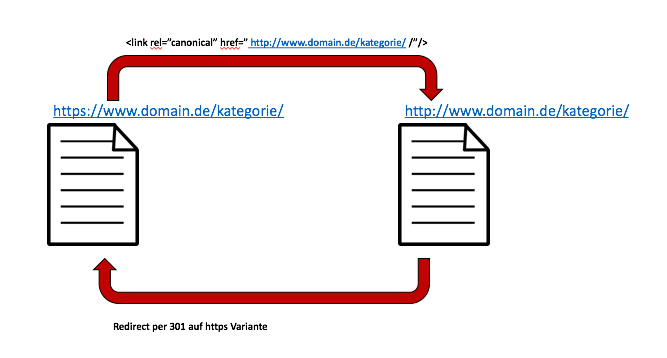
Was ist denn hier passiert?
Die URL https://www.domain.de/kategorie/ besitzt ein Canonical auf die Variante http://www.domain.de/kategorie/. Diese leitet jedoch via 301-Weiterleitung auf die https-Version um. Was wir hier vorfinden, ist ein #canonical301redirectunlimitedloop.
Der Crawler wird ständig bei der Haupt-Ressource hingewiesen, dass die originale URL (kanonische) die URL http://www.domain.de/kategorie/ sei, welche jedoch immer auf die https-Variante umleitet, die einen Canonical Tag auf die http-Variante besitzt.
Überprüft die Canonical Tags stets auf Richtigkeit, um solche Loops zu verhindern. Gut geht das übrigens mit dem Screaming Frog.
Canonical-Weiterleitungsketten
Ähnlich wie bei Weiterleitungen gibt es auch bei Canonical Tags eine lange Kette von Verweisen.
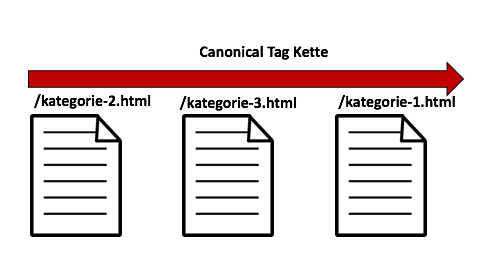
In diesem Beispiel verweist die /kategorie-2.html auf die kanonische URL /kategorie-1.html. Jedoch verweist die /kategorie-1.html mit einem Canonical auf die URL /kategorie-3.html.
An die Suchmaschine werden unklare Signale übermittelt und es kommt zu Indexierungsproblemen.
Achtet darauf, dass das angegebene Ziel in einem Canonical (kanonische URL) die tatsächliche Ziel-URL ist, und nicht auf eine andere weitere URL mittels Canonical Tag verweist.
Fazit:
Bei der Verwendung des Canonical Tags ist höchste Obacht gegeben, denn man kann sich ganz schön was versauen und den Suchmaschinen-Bot unglaublich stark verwirren.
Schreibt gerne in die Kommentare, welche Erfahrungen Ihr mit dem Canonical Tag gemacht habt oder ob Ihr vor einem derzeitigen Problem steht.